
文章图片
文章图片
文章图片
文章图片
哈喽 , 大家好 , 今天我们继续来总结pandas面试题 。
1.隐藏索引
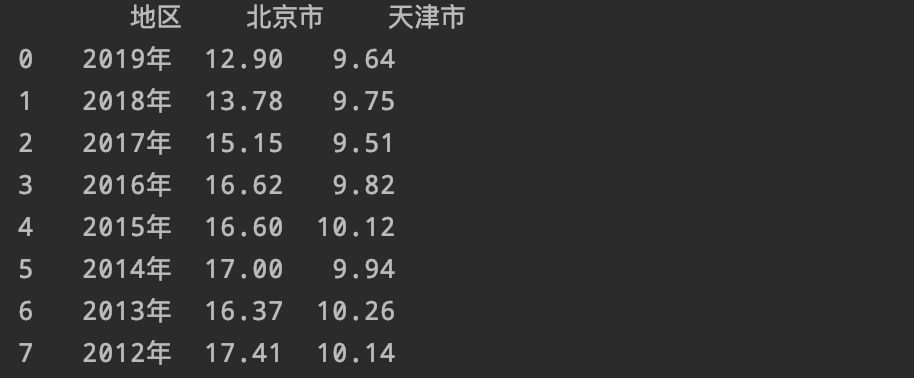
首先我们先导入数据:
import pandas as pd
df=pd.read_excel('北京结婚人数.xlsx')
然后设置好索引:
df.reset_index(drop=True)
然后hide_index进行隐藏索引:
df.style.hide_index()
2.高亮最大值
df.style.highlight_max(axis=0subset=['北京市'
)
3.高亮最小值
df.style.highlight_min(axis=0subset=['北京市'
)
4.高亮空值
df.style.highlight_null(axis=0subset=['北京市'
)
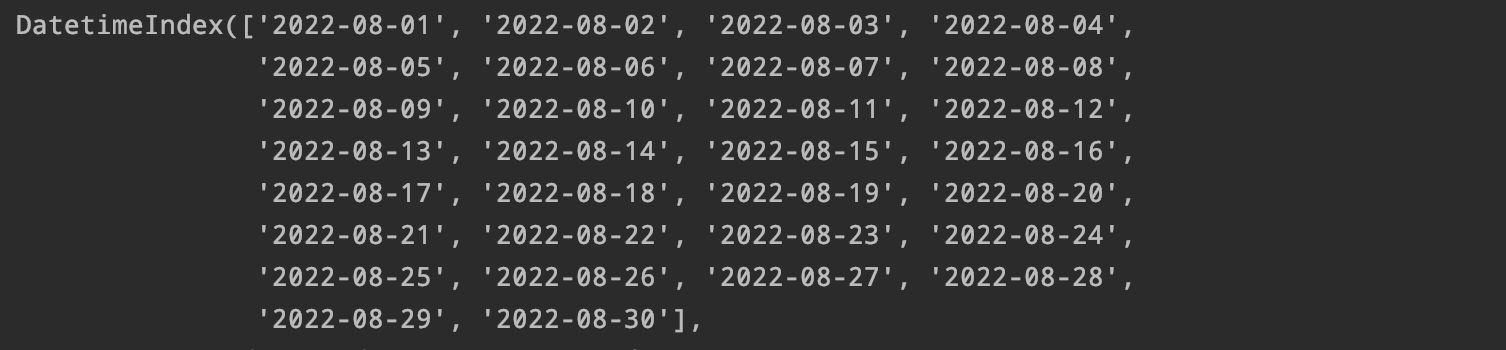
5.设置时间序列:
通过date-range设置好开始和结束的时间
pd.date_range(start='2022-8-01'end='2022-8-30')
同样可以通过频率设置 , 来呈现相同的效果:
df=pd.date_range(start='2022-8-01'periods=30)
6.设置时间戳
通过timestamp函数可以将精确的时间点展示出来:
pd.Timestamp('2022-08-15')
7.截断函数:
我们仍旧以上面的数据为例:
先导入数据:
import pandas as pd
df=pd.read_excel('北京结婚人数.xlsx')
我们通过截断函数 , 只要前5行数据:
df=df.truncate(before=0after=5)
8.merge函数怎么用?
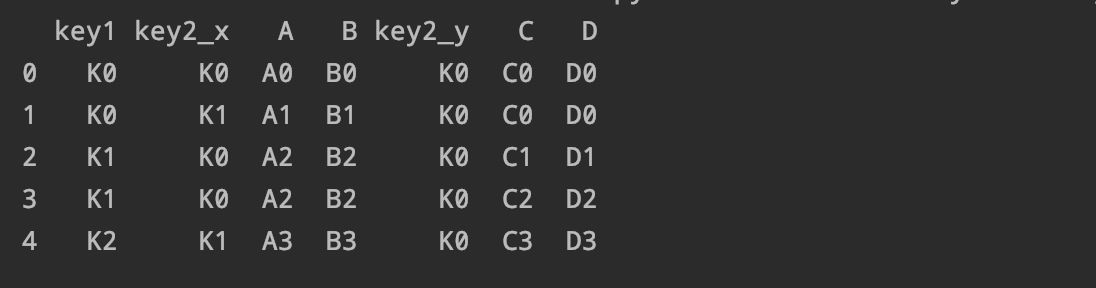
我们先准备两组数据:
left = pd.DataFrame({'key1': ['K0' 'K0' 'K1' 'K2'
'key2': ['K0' 'K1' 'K0' 'K1'
'A': ['A0' 'A1' 'A2' 'A3'
'B': ['B0' 'B1' 'B2' 'B3'
)
right = pd.DataFrame({'key1': ['K0' 'K1' 'K1' 'K2'
'key2': ['K0' 'K0' 'K0' 'K0'
'C': ['C0' 'C1' 'C2' 'C3'
'D': ['D0' 'D1' 'D2' 'D3'
)
【北京市|【全面】pandas数据分析面试题(六)汇总!】我们通过key1进行合并这两组数据:
pd.merge(left right on='key1')
还可以通过多字段连接:
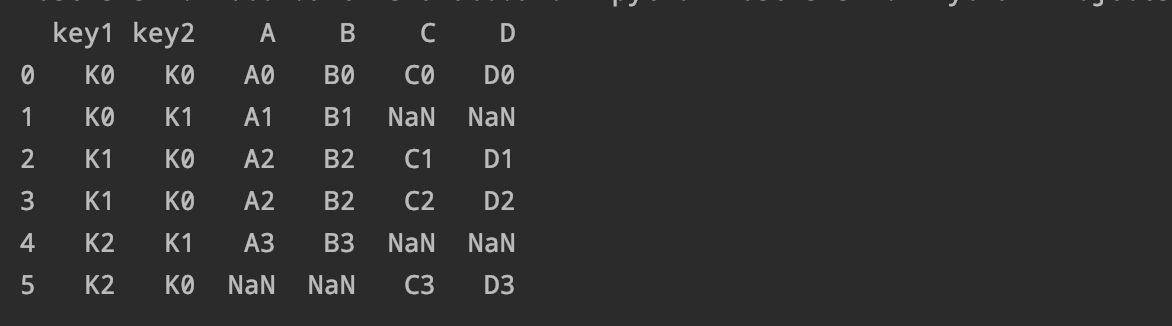
通过inner合并的数据 , 只会留下相同的字段:
pd.merge(left right on=['key1' 'key2'
how='inner')
通过outer合并数据 , 不相同的数据也会保留:
pd.merge(left right on=['key1' 'key2'
how='outer')
- 12月13日消息|小米13系列手机明日开售售价4599元
- 红魔手机|又来一款无刘海无挖孔的第二代骁龙8真全面屏!红魔8 Pro辨识度拉满
- 南京酷科电子科技有限公司作为小米科技公司旗下的生态链企业之一|酷科65wgan充电器测试模块测试模块主要测试
- 最近我们经常遇到这样的购机需求:工作为主|价格真香表现全面的“工作站级设计本”!惠普战99测评
- 高大幕墙骨架结构选型成为当下大跨度幕墙系统面临的主要问题|幕墙精制钢型材,新时代下的幕墙新材料【西创系统】
- IBM|联盟IBM 日本找来2大高手攻关2nm工艺:最快2025年量产
- 短视频剪辑软件,小白也能轻松上手
- mcn|基于Electron框架全面重做:全新Linux版QQ开启公测
- 音频去除杂音剪辑方法简单好用
- 如何将pdf转换成word格式文件?